

Going from 10K to 1M requests per minute
In early 2021, Clubhouse started going through a period of explosive growth. Over the course of two months we went from less than 10K to over 1M backend requests per minute, and we had to quickly adapt to serve billions of requests a day on our existing stack. And we only had two full time backend engineers (we're still tiny though – we are six now – join us!). This is a story about our heat of the moment journey to scale our service and run our Python workloads 3x as efficiently.
Our core Clubhouse web stack is fairly rudimentary — and that's on purpose. We are a Python/Django operation that uses Gunicorn and NGINX. When we started seeing this type of growth, we didn’t have much time to tune for efficiency, and we kept adding more web nodes. We had always just accepted that our Django monolith could only really auto-scale at around 30-35% CPU per instance (like many others have documented) and was destined to be wasteful (blame our co-founder for the choice!). This was an annoying assumption and limitation, but it was never worth the cycles to try to investigate compared to everything else we had to scale and all the other fires we had to put out.
So we added more web nodes — and more and more of them as needed. Throwing machines at the problem was all fine and dandy until we got beyond 1,000 web instances. We were suddenly running one of the larger deployments on our web host. With that many instances, our load balancer began to intermittently time out and leave deploys "stuck" when flipping traffic during blue/green deploys. We tried chasing down the timeouts with our cloud provider but they were not able to root cause why this was happening.
One easy solution would be to run larger instances!
And that's immediately where we headed. But upon switching to the very large 96 vCPUs instance type — running 144 Gunicorn workers on each node — we were shocked to find that latencies began to balloon at just 25% CPU. At that embarrassingly low threshold, our p50 latency skyrocketed and the nodes became unstable.
We were stumped. We spent hours prowling for some system-level limitations. (Surely, it was some random kernel limit or resource that we were silently hitting…) Instead, what we found was far more shocking: only 29 of our 144 Gunicorn processes on these enormous (and expensive) machines were receiving any requests at all! The other 115 processes were sitting idle.
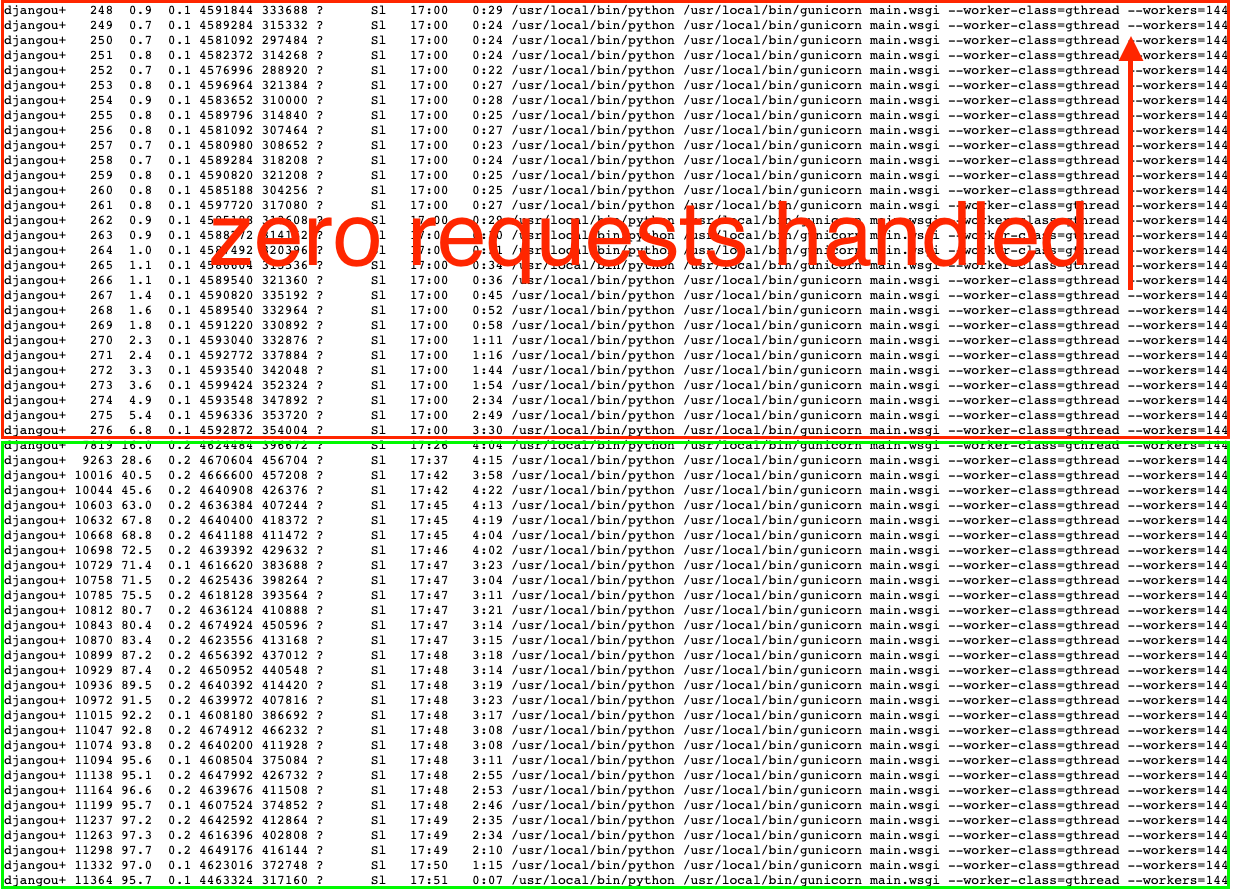
This was... annoying.
As it turns out, this is another instance of the thundering herd problem — and it happens when a large number of processes are trying to wait on the same socket in order to handle the next request that comes in. Unless you explicitly handle the problem, you end up doing something naïve — and all your processes fight to handle the next request, wasting a lot of resources in the process. Turns out, this is a well documented limitation of Gunicorn.
So, what was a growing web service to do? We needed a quick solution with very little engineering bandwidth.
Attempt#1: uWSGI
The first experiment in our journey was to switch our python app server from Gunicorn to uWSGI, which has an elaborate solution to our exact issue built-in. (The documentation about it is worth reading!) The solution is a flag called "--thunder-lock" that does a very fancy thing with the kernel to spread the load evenly across all 144 of our processes.
We quickly deployed uWSGI to replace Gunicorn and, much to our delight, average latency dropped by 2x! Load was now spread evenly across all 144 processes. All seemed well. The emoji reactions piled in on Slack. This graph is gravy!
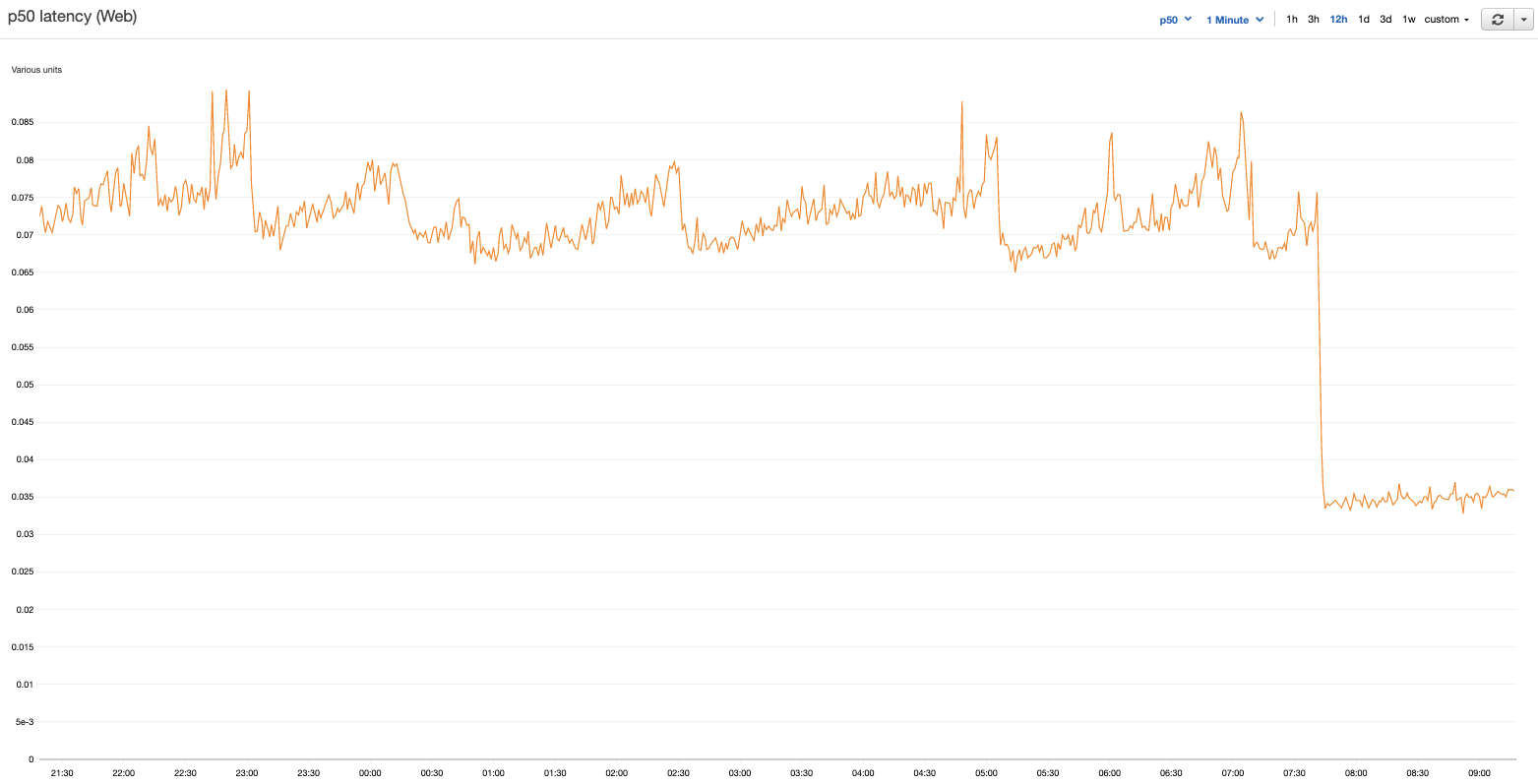
Except, there was one major problem. (Of course there was a problem.)
As we began to ramp up traffic beyond the mysterious 25% CPU threshold from our Gunicorn days, we began to run into an even bigger issue: The uWSGI socket would lock up at unpredictable intervals on some machines. While uWSGI was locked up, the webserver would reject all requests for a period of seconds — during which we'd see large spikes in latency and 500s. Kind of a deal-breaker, eh?
The issue was mysterious. We matched up cryptic log lines alongside uWSGI documentation and StackOverflow posts — even translating posts from German and Russian — but couldn’t find a smoking gun.
Which exacerbated another problem: uWSGI is so confusing. It’s amazing software, no doubt, but it ships with dozens and dozens of options you can tweak. So many options meant plenty of levers to twist around, but the lack of clear documentation meant that we were frequently left guessing the true intention of a given flag.
In the end, we were unable to reliably reproduce or alleviate the problem. We found GitHub issues like this one full of random folks flailing on similar issues.
So uWSGI was not for us. We were back to square one: how can we utilize 100% of the CPU on our app servers?
Attempt #2: NGINX
One theory we tested in the depths of our uWSGI issues was to run ten different versions of uWSGI on each app server to lessen the impact and load balance them with NGINX (our existing web proxy). The thinking went that if one of the sockets were to lock up or implode, we'd at least only suffer 10% of the damage.
This turned out to be a mistake, as NGINX’s load balancing features are severely limited. There are no options to limit concurrency per socket or to prevent the hung sockets from receiving new requests.
Which led us to the question: Why are we using NGINX anyway? Many of the really useful load balancing features are gated by “NGINX Plus,” but we weren’t sure those would help us anyway.
That's when we had the crazy idea.
We knew that Gunicorn performed well enough on its own, but it was extremely poor at load balancing requests across its workers. (That’s why we saw the 115 idle worker processes in the first place.)
What if instead of running ten Gunicorn servers on each server, we went all out and ran a full 144 separate Gunicorn master processes, each with only one web worker? If we could find a way to actually load balance across these workers, surely it would result in perfectly balanced, perfectly behaving extra-large web node.
Attempt #3: HAProxy to the rescue!
Fortunately, HAProxy does everything NGINX could and more for our use case. It would allow us to:
- Evenly distribute requests across 144 backends (Gunicorn sockets)
- Limit concurrency on a per-backend basis — this way we only ever send each Gunicorn socket a single request to not stress it out
- Queue requests in a single place — the HAProxy frontend — rather than a separate backlog on each Gunicorn process
- Monitor concurrency, error rate, and latency on both an app server and Gunicorn socket basis.
We used supervisord to start each Gunicorn socket and simply list out each of the 144 Gunicorn sockets in our HAProxy backend.
We validated the assumption and squeeze tested a single 96 core instance till CPU saturation. In practice, our workload means that we begin to experience higher latencies around 80% CPU, as temporarily spikes due to uneven load saturate the machines. (Today, we choose to scale lower than that to ensure we can withstand 2x bursts before autoscaling kicks in — but we feel pretty good about the available headroom!)
The solution feels a bit ridiculous at first blush, but is it any less ridiculous to do load balancing inside Gunicorn instead? Having many smaller web nodes also causes all sorts of problems with connection pooling — it turns out that having really big instances is great for a number of peripheral reasons besides CPU utilization!
What are our key takeaways from this?
- If uwsgi thunder-lock works for you from the jump — maybe give it a shot! It’s amazing software.
- If you are using NGINX as a sidecar proxy in front of your app, consider adapting your config to use HAProxy instead. You’ll get amazing monitoring and queueing features as a result.
- Python's model of running N separate processes for your app is not as unreasonable as people might have you believe! You can achieve reasonable results this way, with a little digging.
Thanks for reading! Like debugging problems like this with a small, nimble team? Or better yet, want to help us re-architect the whole damn thing — Check out our new jobs site or email me at luke@clubhouse.com.
— Luke Demi, Software Engineer
This post is part of our engineering blog series, Technically Speaking. If you liked this post and want to read more, click here.



